vagrant5
-
Posts
7 -
Joined
-
Last visited
vagrant5's Achievements
")
Newbie (1/14)
0
Reputation
-
I just tested the new system and I see how it works. This is great!! Yes the chapter content will remain off limits to crawlers, but at least the story listings and summaries, members etc can be crawled. Again, thank you for the change!!
-
Thank you both for your time!
-
Thank you very much for your reply and for submitting the sitemap. I hope it works. I know indexing takes time, so we'll have to check status in a couple of months. But I want to clarify a couple of things: The function I referred to would not get us blacklisted by google. It would only do this if your server presents completely different site and information to the google bot than it does to normal visitors (cloaking or spamdexing). This would not be the case. You would just be using this approach to let Googlebot pass a specific page that blocks its crawling. Lots of sites use a similar approach, including major newspapers, journal publishers, and other content providers, esp those who put up a paywall. Google welcomes this and has a page that addresses a similar issue (in the context of paywalls). Esp note how they say "Keep in mind that Googlebot cannot access pages behind registration or login forms". They have some very relevant suggestions, esp in the "implementation" subsection. For google to index the entire site, it needs to move around the site and follow all the links and index all of that content. Because of the form it can't access the site at all and therefore doesn't index. I am not sure if having an index file would help.
-
Yes I agree and understand that it is not feasible to implement full-text search on the AFF search engine. But it is quite feasible (and very desirable) to let people search for AFF stories on Google, by letting Google index AFF archive. I looked into sitemaps before posting my suggestion about detecting Googlebot via the user-agent. Sitemaps are not going to help. Believe me, google knows that the subdomains (e.g. comics.adult-fanfiction.org) exist. They know from links to the archive in posts on this forum, from DNS records, and from incoming links from elsewhere on the web. The issue is that Googlebot cannot get to any of the content. As you mentioned before, the problem is the hidden "form" submission(s). Googlebot will not submit "forms" and it won't store session information. This is what they are referring to when they say "dynamically generated pages" in the passage you quoted. In technical terms, this means that Google probably won't crawl anything that requires cookies and/or an HTTP POST request. A "POST request" is a form submission. I checked how comics.adult-fanfiction.org works in this respect using Firefox's private browsing mode and Live HTTP headers addon. Basically, when a new visitor comes in that has never visited the site before, they have to get past the WARNING page by submitting a form (POST request) with their date of birth etc, after which they get and keep a cookie that identifies them to AFF server as having submitted said form. This makes sure they don't get asked to submit same WARNING form again for some time. This is the ONLY form (POST request) that is required to get to the stories and to navigate from chapter to chapter. Every time a user requests any page in the archives (e.g. a story chapter), they identify themselves by the cookie to your server, so your server knows they accepted and signed the Warning page. If the cookie is missing, they will see the warning page instead of the story. THIS is the mechanism that prevents Googlebot from seeing and indexing AFF archives. It cannot submit the WARNING form and won't keep cookies. So everytime it follows any link to the archive (e.g. a story), all it sees is the warning page. So do not waste time with sitemaps because it won't help. What is necessary is a way to detect googlebot and let it browse the archive without checking its cookie (and therefore not displaying the WARNING page/form). There are a ton of resources on the web about detecting googlebot, this one being the first result for PHP. I am not sure what the backend of AFF db interface is, but I am pretty sure someone out there has figured out something similar that you can use. Please let me know what you think.
-
Yes it crawls the forums/main domain (see results) but not the archive/stories (see results)
-
Thank you very much for the response. I understand that the internal search would not be able to handle full text search, and we should not consider it as an option. Also I understand and agree that we cannot consider the option of removing the warning page when a visitor first visits AFF. However it IS possible to have google index AFF nonetheless. I'm not sure if this is what you were trying to say, but dynamically generated pages (non-static HTML) CAN be indexed by Google. Blogs (e.g. wordpress, livejournal) are all dynamically generated from a database too and can be indexed. The issue is that Google cannot get past the warning page. Here are instructions from Google about how to recognize Google's crawlers, which should enable AFF to let them through without displaying a warning page. In other words, check whether user-agent is Googlebot, and if so let them through. Everyone else still sees the warning page. I know a lot of sites do this kind of thing. If you are concerned about the impact on performance as Google continues to index, there is a way to tell their crawler to slow down (in google webmaster tools). I really think getting indexed would increase AFF's visibility on the web. Please let me know what you think of the above.
-
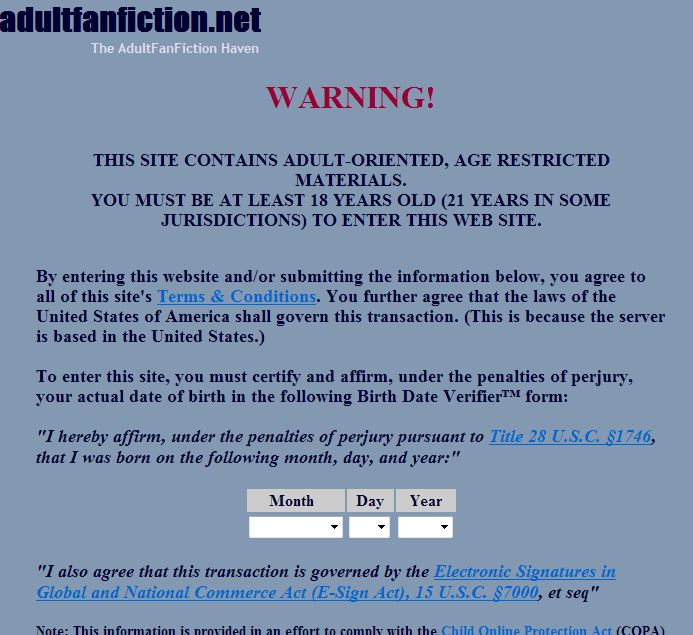
Hi, I think it's a pretty serious issue that we are unable to search the full text of stories in the archive. Only the author, title and summary. From reading some previous posts on the forum I am understanding that such feature could not be supported by the database/server due to likely performance issues (it would be too much of a resource-heavy task). The alternative is just to allow Google to index the site. That way we could just search on goolge without impact on the AFF server. But right now it's not indexed by google at all: this simple search turns up no results. Looking at the robots.txt it looks like Google should be able to index. But there are absolutely no results. I am pretty sure the reason is that there is no way for the google crawler to get past the warning page (see attached). Maybe you can expose some kind of index of the site to google without requiring acceptance of this warning? I am pretty sure there are ways to recognize the crawler too and let it past but make the others click through the warning. In any case, I just wanted to hear the admin's take on this. I think it's pretty important to be able to search full text. Sometimes I want to search for obscure keywords or something else that nobody would ever think about putting in the story "Summary". I definitely think AFF and the authors would get more exposure if the stories appeared on Google.